AI Platforms and CNCF Ecosystem¶
Modern AI systems rely on a complex ecosystem of tools, platforms, and hardware that work together to manage data, train models, deploy services, and scale workloads.
This chapter provides a high-level understanding of the major components that make up the AI platform landscape.
Example Tools¶
| Category | Tool | Purpose |
|---|---|---|
| Workflow orchestration | Airflow, Argo | Schedule and manage jobs |
| Pipeline & MLOps | Kubeflow | End-to-end ML pipelines |
| Experiment tracking | MLflow | Track runs, params, metrics |
| Distributed data/compute | Apache Spark | Large-scale data processing |
CNCF MLOps Toolchains¶
The Cloud Native Computing Foundation (CNCF) ecosystem provides open-source tools that cover the full machine learning lifecycle. These tools help teams automate workflows, track experiments, orchestrate training jobs, and deploy models at scale.
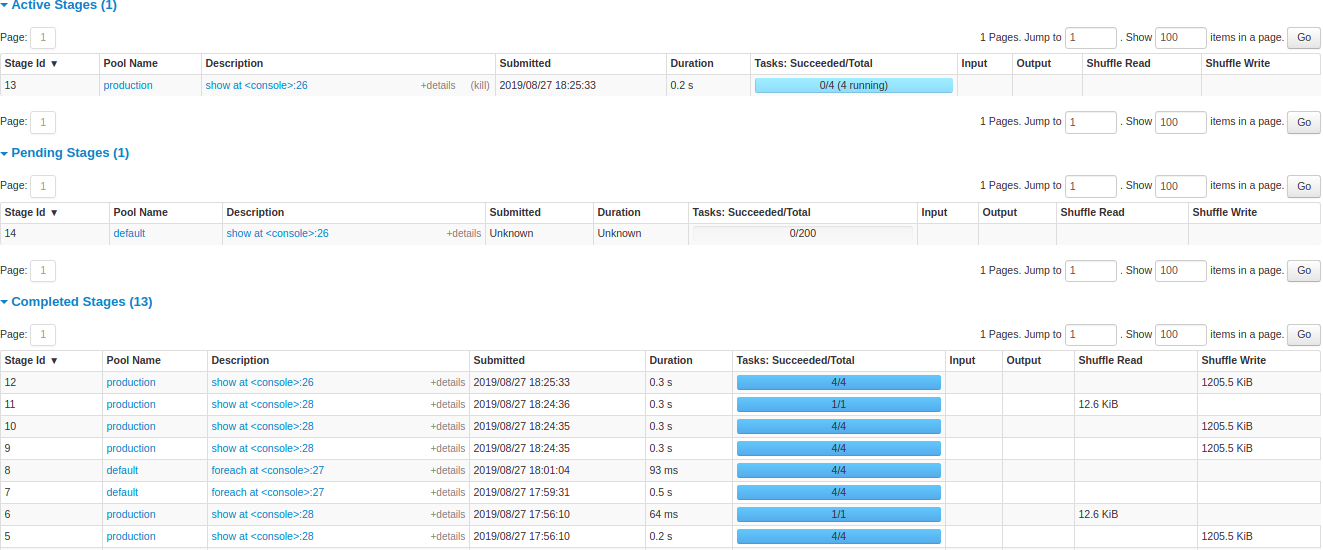
Airflow – Workflow Orchestration¶
- A powerful scheduler for managing end-to-end ML pipelines
- Defines tasks as DAGs (Directed Acyclic Graphs)
- Commonly used for data ingestion, preprocessing, and batch ML workflows
- Integrates with cloud storage, databases, and compute services
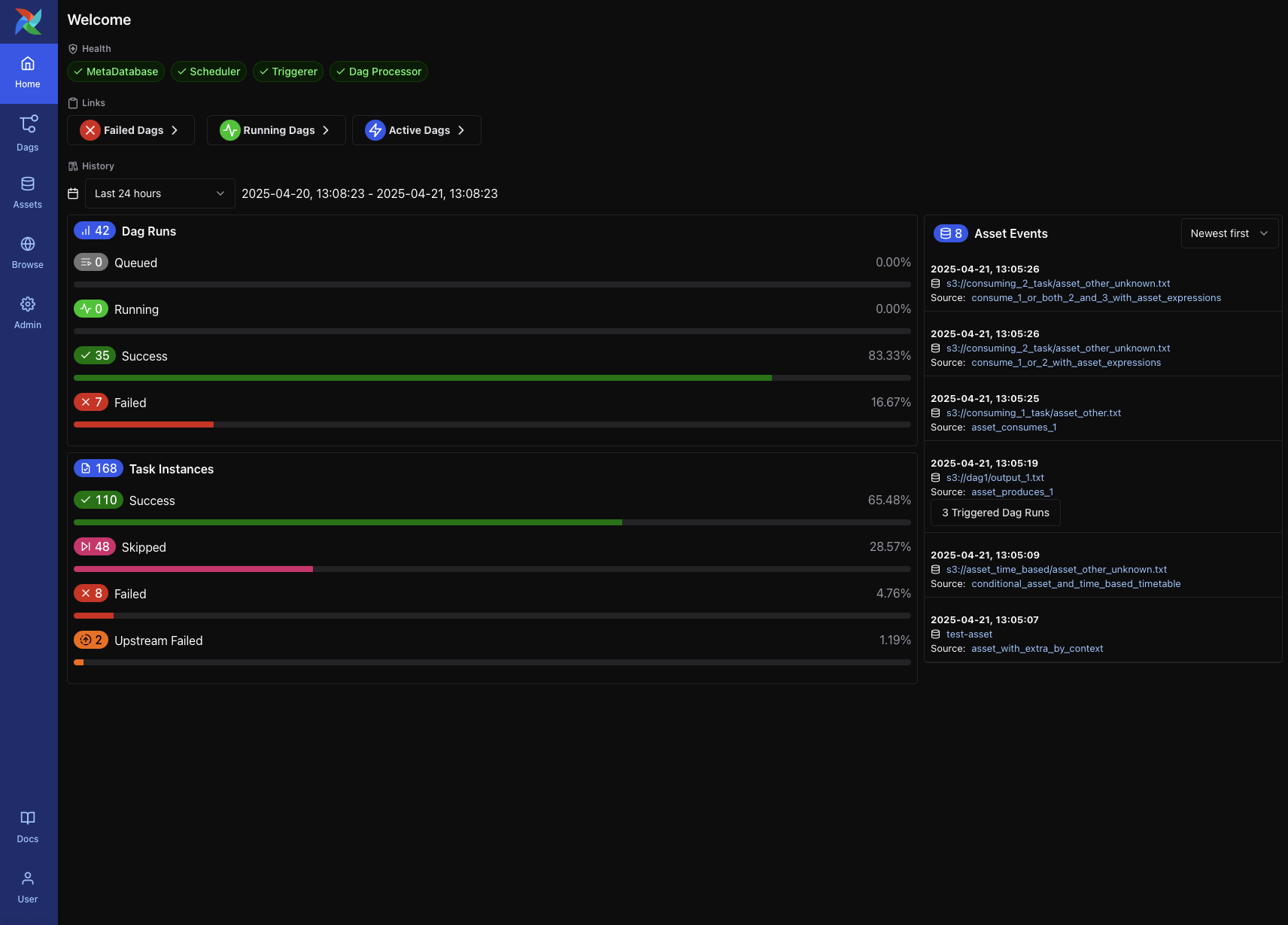
MLflow – Experiment Tracking & Model Registry¶
- Tracks experiments, hyperparameters, metrics, and artifacts
- Provides a standardized format for packaging ML models (MLflow Models)
- Includes a model registry for versioning and promoting models to production
- Framework-agnostic (works with PyTorch, TensorFlow, XGBoost, etc.)
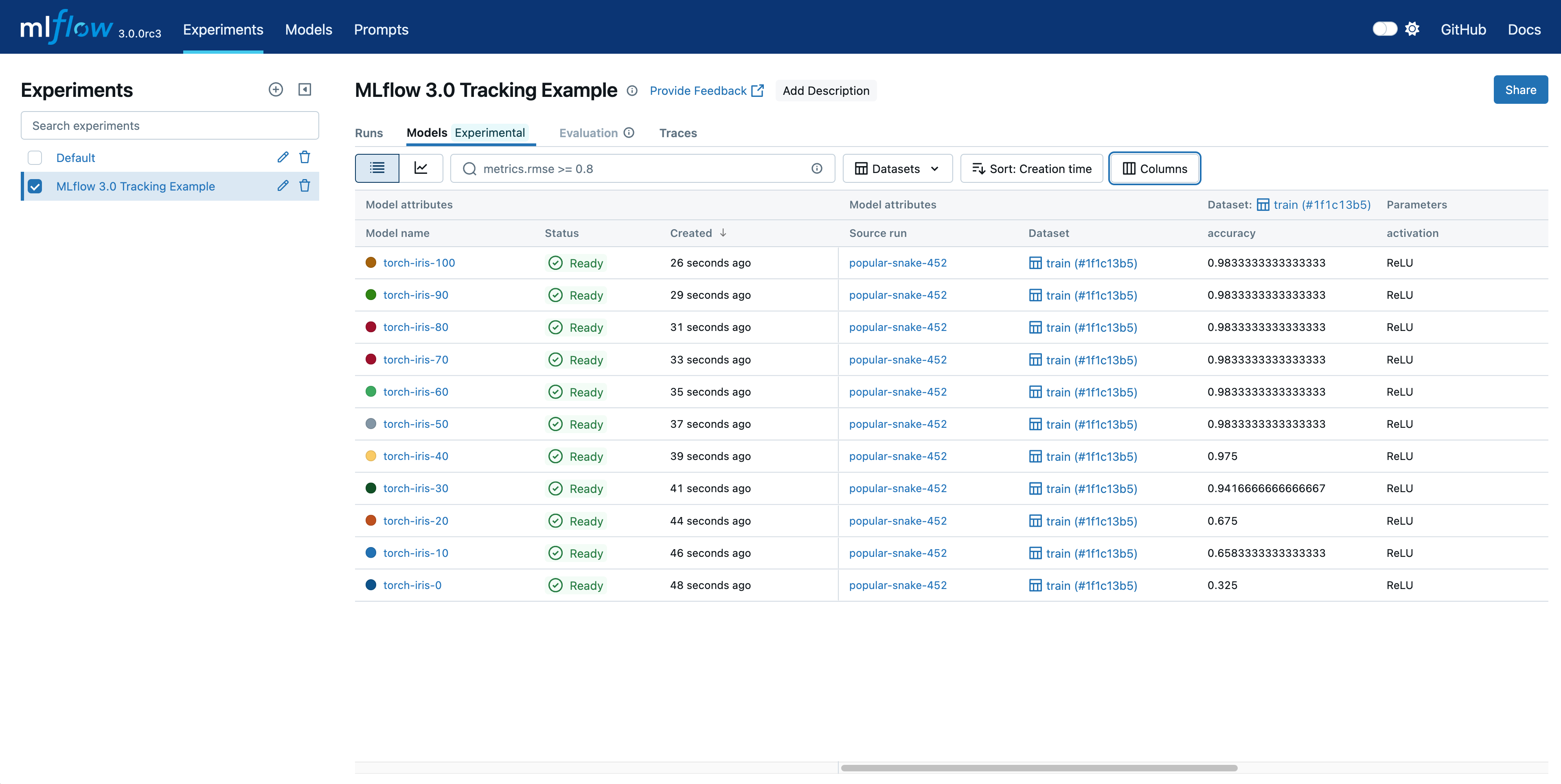
Kubeflow – ML on Kubernetes¶
- A Kubernetes-native platform for training, serving, and managing ML models
- Key components:
- Kubeflow Pipelines – CI/CD for ML workflows
- Katib – Automated hyperparameter tuning
- KFServing / KServe – High-performance model serving
- Ideal for teams using Kubernetes for large-scale ML workloads
Apache Spark – Distributed Data & ML Processing¶
- Distributed data processing engine optimized for large datasets
- Supports SQL, streaming data, and MLlib for scalable machine learning
- Widely used for feature engineering, ETL, and batch training pipelines
- Integrates with Delta Lake, Hudi, Iceberg for large-scale data lakes